Documentation Index
Fetch the complete documentation index at: https://docs.scrapegraphai.com/llms.txt
Use this file to discover all available pages before exploring further.
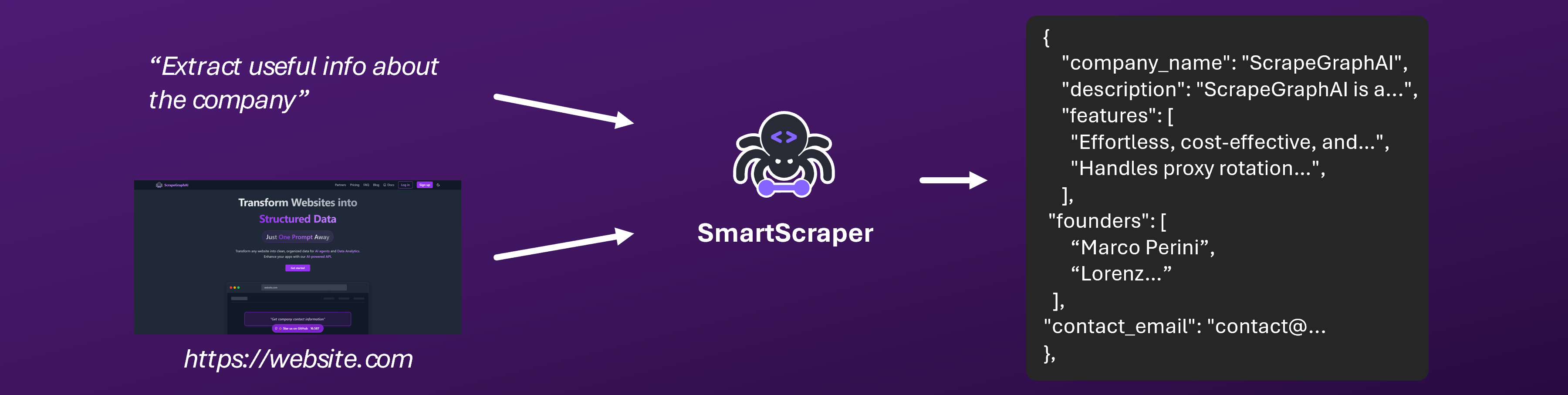
Overview
The ScrapeGraphAI API uses an intelligent proxy system that automatically handles web scraping requests through multiple proxy providers. The system uses a fallback strategy to ensure maximum reliability — if one provider fails, it automatically tries the next one. No configuration required: The proxy system is fully automatic and transparent to API users. You don’t need to configure proxy credentials or settings yourself. In v2, all proxy and fetch behaviour is controlled through theFetchConfig object, which you can pass to any service method (extract, scrape, search, crawl, etc.).
How It Works
The API automatically routes your scraping requests through multiple proxy providers in a smart order:- The system tries different proxy providers automatically
- If one provider fails, it automatically falls back to the next one
- Successful providers are cached for each domain to improve performance
- Everything happens transparently — you just make your API request as normal
Fetch Modes
Themode parameter inside FetchConfig controls how pages are retrieved and which proxy strategy is used:
| Mode | Description | JS Rendering | Best For |
|---|---|---|---|
auto | Automatically selects the best provider chain | Adaptive | General use (default) |
fast | Direct HTTP fetch via impit | No | Static pages, maximum speed |
js | Headless browser rendering | Yes | JavaScript-heavy SPAs |
stealth boolean to true alongside any mode. For example, mode: "js" with stealth: true provides JS rendering through a residential proxy — equivalent to the old js+stealth mode.
Country Selection (Geotargeting)
You can optionally specify a two-letter country code viaFetchConfig.country to route requests through proxies in a specific country. This is useful for:
- Accessing geo-restricted content
- Getting localized versions of websites
- Complying with regional requirements
- Testing location-specific features
Using Country Code
Supported Country Codes
The API supports geotargeting for a wide range of countries using ISO 3166-1 alpha-2 country codes:View All Supported Countries
View All Supported Countries
| Code | Country | Code | Country | Code | Country |
|---|---|---|---|---|---|
us | United States | uk / gb | United Kingdom | ca | Canada |
au | Australia | de | Germany | fr | France |
it | Italy | es | Spain | nl | Netherlands |
be | Belgium | ch | Switzerland | at | Austria |
se | Sweden | no | Norway | dk | Denmark |
fi | Finland | pl | Poland | cz | Czech Republic |
ie | Ireland | pt | Portugal | gr | Greece |
jp | Japan | kr | South Korea | cn | China |
in | India | sg | Singapore | hk | Hong Kong |
mx | Mexico | br | Brazil | ar | Argentina |
cl | Chile | co | Colombia | pe | Peru |
za | South Africa | eg | Egypt | ae | UAE |
sa | Saudi Arabia | il | Israel | tr | Turkey |
ru | Russia | ua | Ukraine | nz | New Zealand |
FetchConfig Reference
All proxy and fetch behaviour is configured through theFetchConfig object:
| Parameter | Type | Default | Description |
|---|---|---|---|
mode | string | "auto" | Fetch mode: auto, fast, js |
stealth | bool | false | Enable stealth mode with residential proxy and anti-bot headers |
timeout | int | 30000 | Request timeout in milliseconds (1000–60000) |
wait | int | 0 | Milliseconds to wait after page load before scraping (0–30000) |
scrolls | int | 0 | Number of page scrolls to perform (0–100) |
country | string | — | Two-letter ISO country code for geo-located proxy routing (e.g. "us") |
headers | object | — | Custom HTTP headers to send with the request |
cookies | object | — | Cookies to send with the request |
mock | bool | false | Enable mock mode for testing (no real request is made) |
Usage Examples
Basic Request (Automatic Proxy Selection)
Request with Country Code
Stealth Mode with JS Rendering
Real-World Use Cases
Accessing Geo-Restricted Content
Getting Localized Content
E-commerce Price Comparison
Best Practices
1. Choose the Right Fetch Mode
Pick the mode that matches your target site:auto(default) — let the system decide; works for most sitesfast— use for simple, static HTML pagesjs— use for SPAs and JavaScript-rendered content- Add
stealth: truefor anti-bot sites — combine with any mode (e.g.,mode: "js"+stealth: truefor dynamic anti-bot sites)
2. Use Country Code When Needed
Only specify a country code if you have a specific requirement:- Accessing geo-restricted content
- Getting localized versions of websites
- Complying with regional requirements
- Don’t specify if you don’t need it — let the system optimize automatically
3. Let the System Handle Routing
The API automatically selects the best proxy provider for each request:- No manual proxy selection needed
- Automatic failover ensures reliability
- Performance is optimized automatically
4. Handle Errors Gracefully
If a request fails, the system has already tried multiple providers:5. Monitor Rate Limits
Be aware of your API rate limits:- The proxy system respects these limits automatically
- Monitor your usage in the dashboard
- Implement appropriate delays between requests
Troubleshooting
Request Failures
Request Failures
Request Failures
If your scraping request fails:
- Verify the URL: Make sure the URL is correct and accessible
- Check the website: Some websites may block automated access regardless of proxy
- Try a different mode: Use
mode: "js"withstealth: truefor heavily-protected sites - Retry the request: The system uses automatic retries, but you can manually retry after a delay
- Try a different country: If geo-restriction is the issue, try a different
country
Rate Limiting
Rate Limiting
Rate Limiting
If you receive rate limit errors (HTTP 429):
- Wait a few minutes before making new requests
- The API automatically handles rate limits on proxy providers
- Consider implementing exponential backoff in your application
- Check your API usage limits in the dashboard
Geo-Restricted Content
Geo-Restricted Content
Geo-Restricted Content
If you’re trying to access geo-restricted content:
- Use the
countryparameter insideFetchConfigto specify the required country - Make sure the content is available in that country
- Some content may still be restricted regardless of proxy location
- Try multiple country codes if one doesn’t work
Anti-Bot Protection
Anti-Bot Protection
Anti-Bot Protection
If a website is blocking your requests:
- Set
stealth: trueinFetchConfig(combine withmode: "js"for dynamic sites) - Add a
waittime to let the page fully load - Use
scrollsto trigger lazy-loaded content - Add custom
headersif the site expects specific ones
FAQ
Do I need to configure proxy credentials?
Do I need to configure proxy credentials?
A: No, the proxy system is fully managed and automatic. You don’t need to provide any proxy credentials or configuration.
How do I control the proxy strategy?
How do I control the proxy strategy?
A: Use the
mode parameter in FetchConfig (auto, fast, or js) and set stealth: true when you need residential proxy with anti-bot headers.Can I choose which proxy provider to use?
Can I choose which proxy provider to use?
A: No, the system automatically selects the best proxy provider for each request. You can influence the strategy by setting the
mode parameter.What happens if all proxies fail?
What happens if all proxies fail?
A: The API will return an error. The system tries multiple providers with automatic fallback, so this is rare. If it happens, verify the URL and try again.
Does using country cost more?
Does using country cost more?
A: No, the
country parameter doesn’t affect pricing. Credits are charged the same regardless of proxy location.Can I use FetchConfig with all services?
Can I use FetchConfig with all services?
A: Yes,
FetchConfig is available for all services including extract, scrape, search, crawl, and monitor.What's the difference between 'uk' and 'gb' country codes?
What's the difference between 'uk' and 'gb' country codes?
A: Both
uk and gb refer to the United Kingdom. The API accepts both codes for compatibility.Support & Resources
API Reference
Detailed API documentation
Dashboard
Monitor your API usage and credits
Community
Join our Discord community
GitHub
Check out our open-source projects
Need Help?
Contact our support team for assistance with proxy configuration, geotargeting, or any other questions!